

Les modèles de Deep Learning appliqués aux séries temporelles ont-ils un intérêt limité en production ?

Le domaine de la prévision des séries temporelles est en pleine évolution. D’un côté, les conférences voient une prolifération de nouveaux modèles de Transformers dédiés à cette tâche. De l’autre, dans les projets de forecasting en production, les modèles ensemblistes comme LGBM dominent largement, tandis que les approches de Deep Learning sont presque absentes. Cela soulève une question cruciale : les modèles de Deep Learning ont-ils vraiment un intérêt limité en production ?
Dans cet article, nous allons explorer cette problématique en testant un de ces modèles sur des données réelles, pour voir s’ils peuvent rivaliser avec les approches traditionnelles.
A travers ce benchmark nous visons à comparer les modèles de Deep Learning pour les séries temporelles, en mettant un accent particulier sur ceux basés sur les Transformers. Nous nous concentrerons sur leur utilisation pour le forecasting. Nous avons sélectionné un jeu de données qui nous parait intéressant et pertinent. Il est particulièrement adapté car il représente des données réelles, imparfaites, open source et proviennent d’une source française. Cela nous permettra également d’ajouter des données exogènes appropriées : la consommation d’électricité des foyers en France (lien).
Nous comparons les performances de ces modèles avec celles d’un LGBM, modèle de Machine Learning très utilisé aujourd’hui au vu de ses performances pour la prédiction de séries temporelles.
À travers cet article, nous présentons les modèles et les données choisis pour ce benchmark ainsi que les résultats obtenus.
Vous pouvez également retrouver le code utilisé dans cette étude ici.
Introduction
État des lieux des modèles TS : LGBM et RandomForest
Actuellement, les modèles les plus répandus dans le forecasting de séries temporelles sont les modèles ensemblistes tels que le LGBM et le RandomForest. Leur réputation (M5 Competition results and findings) repose sur leurs performances solides ainsi que sur leurs faibles temps d’entraînement et d’inférence.
Ces modèles exploitent les séries temporelles sous forme de données tabulaires, en construisant des variables basées sur les données historiques et temporelles (comme les décalages temporels, les fenêtres glissantes, etc.). De plus, ils peuvent intégrer des données exogènes, c’est-à-dire des variables extérieures qui influent sur une série temporelle mais sont externes au système de prévision. Par exemple, pour prédire les ventes d’un produit, des variables exogènes pourraient inclure des facteurs économiques comme le revenu des consommateurs, des données météorologiques, ou des événements spéciaux tels que les vacances ou les promotions.
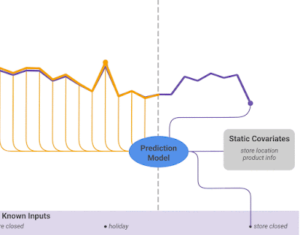
Figure 1 : Prédiction avec entrées connues et covariables statiques
Cependant, ces modèles présentent quelques inconvénients. Ils exigent un travail important de Feature Engineering pour optimiser les performances. De plus, leur capacité à gérer de très grandes quantités de données est relativement limitée en termes de temps de calcul et de mémoire par rapport aux approches basées sur le Deep Learning.
Modèle LGBM
LightGBM (Light Gradient Boosting Machine) est un modèle fondé sur les arbres de décision et le renforcement par gradient. Ce dernier, également connu sous le nom de boosting, fait référence à une approche de Machine Learning consistant à utiliser plusieurs modèles avec le même algorithme, créant ainsi un modèle agrégé plus puissant pour résoudre un problème donné ; contrairement à la méthode de bagging, où plusieurs modèles sont entraînés de manière indépendante en parallèle. Enfin, un système de vote est utilisé pour intégrer les prédictions de chaque modèle dans le résultat final.
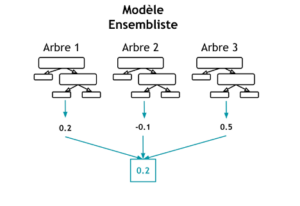
Figure 2 : Prédiction par modèle ensembliste
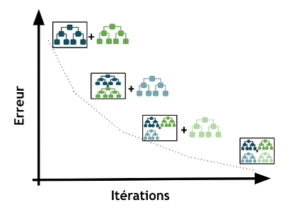
Figure 3 : Réduction de l’erreur par itérations successives (Gradient Boosting)
Dans le fonctionnement du modèle, les arbres de décisions sont combinés de telle sorte que chaque nouvel arbre apprenne en ajustant les différences entre les prédictions du modèle actuel et les valeurs réelles , améliorant ainsi les performances globales du modèle. Le LGBM se distingue par sa rapidité et ses performances élevées.
Les modèles de Deep Learning
Cela nous amène ainsi au Deep Learning qui commence aujourd’hui à démontrer des résultats prometteurs dans l’analyse des séries temporelles.
Les avantages et limites
Les modèles de Deep Learning présentent plusieurs avantages potentiels :
- Leur structure est adaptée pour capturer des motifs complexes et hiérarchiques dans les séries temporelles, ce qui leur permet de détecter des relations subtiles et non linéaires entre les différentes variables temporelles. Cette capacité peut conduire à des performances de prédiction améliorées.
- De plus, ils peuvent s’adapter à différentes longueurs de séries temporelles et gérer de très longues séquences, offrant ainsi une grande flexibilité dans leur utilisation.
- Enfin, comme mentionné précédemment, les réseaux de neurones profonds ont la capacité d’apprendre, de manière automatique : ils réussissent à extraire les caractéristiques pertinentes à partir des données brutes, telles que les corrélations, les lags, etc. Cela simplifie considérablement le processus de prétraitement des données, ce qui peut être un avantage significatif dans de nombreux cas.
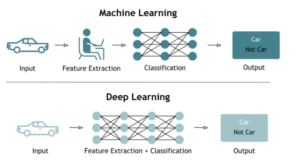
Figure 4 : Comparaison des processus d’apprentissage du Machine Learning et du Deep Learning
Cependant, il est important de noter que le choix entre Deep Learning et les approches traditionnelles de Machine Learning dépendra de plusieurs facteurs, tels que :
- La quantité de données disponibles (quelques milliers d’observation ou centaines de milliers) ;
- La complexité des motifs temporels à capturer ;
- Les ressources informatiques disponibles (GPU) et la facilité de mise en œuvre.
Les approches traditionnelles de Machine Learning peuvent dans une majorité de cas être assez performant quand la bonne quantité de données est disponible, avec des ressources informatiques très modeste. En revanche, la complexité des modèles de Deep Learning peut entraîner des défis en termes de temps de calcul et de ressources computationnelles nécessaires même avec peu de données disponibles sans garantie d’une performance similaire.
Les Transformers
Dans le Deep Learning, on peut également trouver les modèles basés sur les Transformers, tels que GPT (Generative Pre-trained Transformer), qui ont établi de nouvelles normes en matière de génération de texte et de compréhension contextuelle.
Ces modèles reposent sur le mécanisme d’auto–attention, qui consiste à calculer une pondération pour chaque élément d’une séquence en fonction de ses relations avec tous les autres. Cette approche permet ainsi de capturer les dépendances à long terme et de saisir les relations contextuelles dans le traitement du langage naturel. Pour une compréhension approfondie du sujet des Transformers et du mécanisme de self-attention, nous vous conseillons cet article d’Harvard.
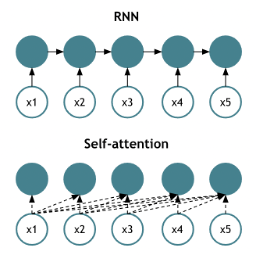
Figure 5 : Comparaison du mécanisme d’auto-attention et d’un RNN
- Les cercles bleus représentent les unités de traitement (neurones) ;
- Les flèches indiquent le flux d’informations ;
- Les lignes pointillées dans le mécanisme d’auto-attention représentent les relations d’attention calculées entre les différentes entrées ;
- Imaginez désormais les données d’entrée (x1, x2, etc.) correspondent à des mots (« je », « suis », etc.) :
- Le RNN les traite de manière séquentielle, chaque étape prenant en compte la sortie de l’étape précédente ;
- Le mécanisme d’auto-attention les traite simultanément, chaque élément étant mis en relation avec tous les autres.
Désormais, les Transformers ont également été adaptés aux séries temporelles, permettant ainsi de capturer des dépendances à long terme et de gérer des séquences de longueur variable.
Parmi ces modèles, nous retrouvons l’Informer, l’Autoformer, le Pyraformer et le Temporal Fusion Transformer (TFT). Dans ce benchmark nous avons choisi d’entrainer un TFT notamment pour sa capacité d’intégrer différents types de données exogènes que la majorité des autres modèles Transformers ne proposent pas.
Le Temporal Fusion Transformer (TFT) offre à la fois une prévision multi-horizon et des dynamiques temporelles interprétables, tout en maintenant des performances élevées. Cela signifie que le TFT ne se contente pas de prédire, il explique. Il identifie les facteurs clés qui influencent les résultats futurs (ex : saisonnalité, publicité) et comment leur impact évolue dans le temps (ex : effet décroissant d’une campagne).
Cette combinaison de précision et d’interprétabilité en fait un outil précieux pour la prise de décision dans de nombreux domaines.
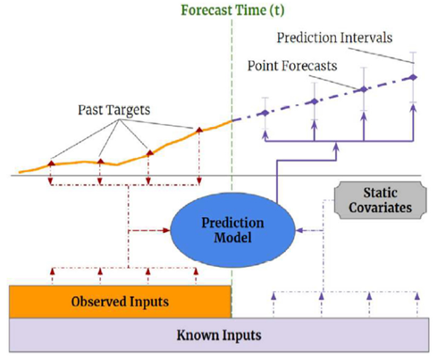
Figure 6 : Avantages du TFT
Pour apprendre les relations temporelles à différentes échelles, le TFT utilise une approche hybride. Il combine des couches récurrentes pour le traitement local et des couches d’auto-attention interprétables pour capturer les dépendances à long terme. De plus, il intègre des composants spécialisés pour sélectionner les caractéristiques pertinentes et une série de couches de filtrage pour éliminer les composants non essentiels, ce qui contribue à maintenir des performances élevées dans une variété de scénarios.
La solution s’avère particulièrement adaptée aux problèmes en temps réel et peut traiter une variété de types de variables d’entrée, ce qui en fait un choix attrayant pour de nombreux domaines d’application.
L’architecture novatrice du Temporal Fusion Transformer (TFT) repose sur plusieurs éléments clés :
- Couches récurrentes pour le traitement local : ce qui lui permet de saisir finement les données à court terme ;
- Couches d’auto-attention pour les dépendances à long terme : cela permet au modèle de prendre en compte des dépendances temporelles plus larges et complexes ;
- Mécanisme de filtrage pour éviter les composants inutilisés : cela permet d’améliorer ainsi l’efficacité et la précision des prévisions ;
- Réseau de sélection de variables pour choisir les entrées pertinentes : cela permet de réduire ainsi la complexité du modèle et améliorant la performance ;
- Encodeurs de covariables statiques : ce qui permet de prendre en compte des informations constantes dans les prévisions ;
- Prédiction via la prévision des quantiles : ce qui offre ainsi une estimation plus robuste de l’incertitude associée aux prévisions.
Pour avoir plus de détails, voici le lien du papier.
En combinant ces éléments, la solution apportée par le TFT offre une approche complète et performante pour la prévision multi-horizon. Cette architecture permet de traiter des problèmes en temps réel avec une variété de types de données d’entrée, tout en fournissant des prévisions précises et interprétables, ainsi qu’une sélection adaptative de variables pour une efficacité optimale.
Nous retrouvons donc différents types de données d’entrée :
- Variables statiques (static covariates) : constantes dans le temps, elles offrent des informations supplémentaires comme les détails des produits, des utilisateurs, emplacements géographiques, etc. ;
- Variables observées (observed inputs) : disponibles au moment de la prédiction et jusqu’à un certain point dans le temps, elles sont utilisées pour entrainer le modèle, comprenant des données historiques telles que les ventes passées ou les conditions météorologiques ;
- Variables connues (known inputs) : disponibles et connues pour toute la période temporelle couverte par les données (dont la période de prédiction, contrairement aux variables observées), elles peuvent être des variables constantes dans le temps comme des caractéristiques de produits ou les jours fériés.
Les données utilisées
Les données utilisées dans cette étude proviennent d’Enedis, sur la consommation d’électricité des foyers en France.
| Caratéristiques | Enedis | |
|---|---|---|
| Source | OpenData Enedis | |
| Fréquence | 30 minutes | |
| Target | Volume d'électricité consommé (Wh) | |
| Historique utilisé | 20/08/2018 - 31/12/2022 | |
| Données exogènes | Statiques | Régions, puissance, etc. |
| Dynamiques | Points de soutirage | |
| Autres à disposition | Courbe moyenne, etc. | |
| Nombre de séries temporelles | 135 | |
Nous avons également ajouté des données météorologiques telles que la température, les précipitations et la pression.
En utilisant ces données, nous disposons d’un total de 135 séries temporelles provenant d’Enedis, nous permettant ainsi d’explorer une variété de scénarios et de contextes dans notre étude.
Résultats
Nous avons donc pu exposer les modèles et les données utilisés, et avant de présenter l’entraînement des modèles et les résultats, nous allons détailler la phase de Feature Engineering effectuée, spécifique au modèle LGBM.
Feature Engineering pour le LGBM
Nous avons préparé les données pour l’entraînement du modèle LGBM, en réalisant un processus de Feature Engineering afin d’extraire des informations pertinentes et de les intégrer au modèle :
- Calcul des lags : nous avons généré des variables représentant les observations précédentes (lags) pour chaque observation de la cible (target dans le dataset). Ces nouvelles variables incluent des statistiques agrégées telles que la moyenne et la médiane de la cible sur une période déterminée ;
- Variables calendaires : le jour de la semaine, le mois, le jour du mois, la saison et l’heure ;
- Variables météorologiques: la température, les précipitations et la pression atmosphérique ;
- Encodage des variables non numériques.
Ces nouvelles variables ont été utilisées comme entrées pour le modèle LGBM afin de prédire la variable cible finale. Ce processus très laborieux de Feature Engineering vise à enrichir les données d’entrée et à fournir au modèle des informations pertinentes pour améliorer sa capacité à effectuer des prédictions précises. En revanche, pour les modèles de Deep Learning, ceci n’est pas nécessaire car le modèle apprend ces relations pendant l’entrainement.
Entrainement des modèles
LGBM
Pour entraîner ce modèle, nous avons divisé notre jeu de données Enedis en deux parties distinctes afin d’assurer la robustesse du modèle final :
- Période d’entraînement : 01/01/2021 à 31/12/2022. Sur cette période, le modèle est exposé aux données pour apprendre les relations entre les variables et développer sa capacité de prédiction ;
- Période de test : 01/01/2023 à 31/03/2023. Une fois que le modèle a été entraîné et validé, cette période est utilisée pour évaluer sa performance finale sur des données entièrement nouvelles et indépendantes. Cela nous donne une indication de la capacité du modèle à faire des prédictions précises dans des conditions réelles.
Cette approche de division en différents ensembles d’entraînement et de test nous permet de garantir un modèle généralisable et capable de faire des prédictions fiables sur de nouvelles données, tout en nous permettant de l’ajuster et le valider de manière rigoureuse.
Validation croisée pour séries temporelles :
Pour évaluer notre modèle final, nous avons utilisé la technique de cross-validation temporelle, spécialement conçue pour les modèles de Machine Learning – tenant compte de la séquentialité des données temporelles. Cette approche est nécessaire pour éviter d’entrainer le modèle avec des valeurs futures pour prédire des valeurs passées.
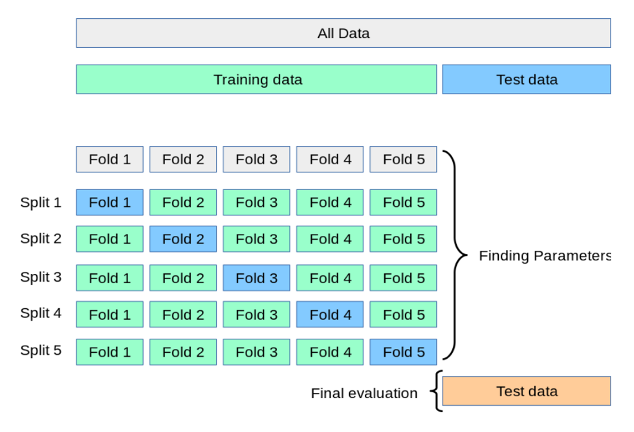
Figure 8 : Validation croisée pour les séries temporelles
Dans cette méthode, les données sont divisées en ensembles chronologiques distincts, chacun étant utilisé à tour de rôle comme ensemble d’entraînement, ensemble de validation et ensemble de test. Cette rotation garantit que le modèle est évalué sur des données futures par rapport à celles sur lesquelles il a été entraîné, ce qui est crucial pour évaluer sa capacité de généralisation dans des conditions réelles.
Il est important de noter que le choix de l’horizon de prédiction influence cette séparation à chaque fois. Par conséquent, une attention particulière est portée à la définition de cet horizon pour garantir une évaluation précise et significative du modèle.
TFT
Pour le modèle de Deep Learning (TFT) la validation croisée temporelle classique coute très chère en termes de ressources et de temps. Pour cette raison nous avons implémenté une approche sensiblement différente où nous avons fait des modifications sur la partie de validation et test afin de couvrir un périmètre plus large et assurer une généralisation du modèle : en effet le modèle est entrainé sur la partie d’entrainement et validé sur des échantillons aléatoires de la partie validation puis testé sur la partie test.
Pour cela, nous avons divisé notre jeu des données en trois parties :
- Période d’entraînement : 01/01/2021 à 31/12/2021.
- Période de validation : 01/01/2022 à 31/12/2022. Cette période est utilisée pour évaluer les performances du modèle et ajuster ses hyperparamètres. Cela nous permet de surveiller la capacité du modèle à généraliser sur des données qu’il n’a pas vues pendant l’entraînement ;
- Période de test : 01/01/2023 à 31/03/2023.
Pour résumer, à chaque époque, une fois le modèle passé sur les données de la période d’entraînement, il passe sur un échantillon des données de validation. Cela lui permet de diriger la loss (fonction de perte) de manière à améliorer les performances sur l’ensemble de validation.
L’ensemble de test nous permet de mesurer la performance du modèle et de comparer avec les résultats obtenus avec le modèle LGBM.
Performances
Nous avons décidé de nous concentrer sur le dataset Enedis, et nous avons donc entraîné et optimisé plusieurs modèles LGBM et TFT sur différents horizons de prédiction, en explorant diverses combinaisons de variables exogènes. Pour comparer ces résultats, nous avons utilisé la WMAPE (Weighted Mean Absolute Percentage Error), car elle fournit une mesure intuitive et équitable de l’erreur des prédictions en pourcentage, par rapport aux valeurs réelles dans les séries temporelles : elle mesure de combien dévie le modèle, en %, de la réalité.
Voici un aperçu de nos résultats pour les différents cas étudiés, sur la période de test.
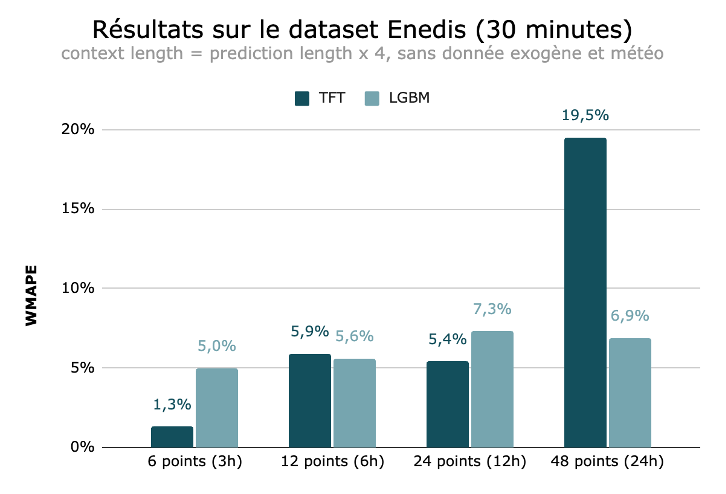
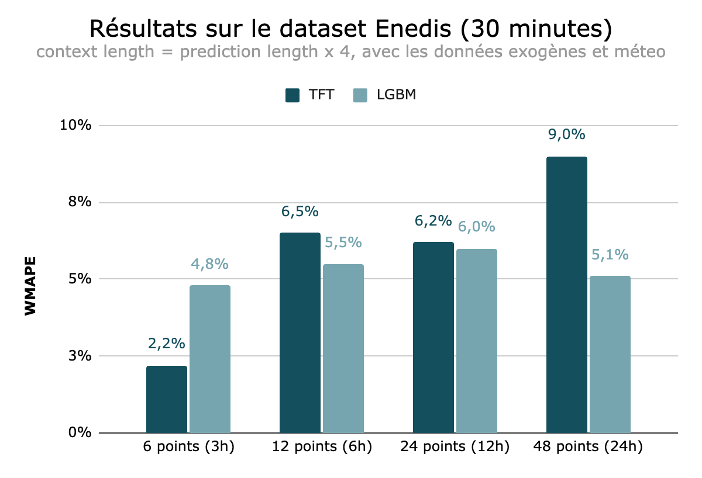
Ces résultats suggèrent que le modèle TFT est plus performant que le LGBM pour des prédictions à très court terme (horizons de 3 heures). Cependant, pour des horizons de prédiction plus lointains, le LGBM montre des performances comparables voire meilleures.
Finalement, il semble que le TFT soit plus sensible à des horizons de prédiction plus longs et à l’absence de données exogènes, ce qui se traduit par des erreurs plus importantes dans ces conditions. Il obtient les meilleurs résultats à court terme et sans données exogènes. Cela peut être traduit par des données météorologiques très générales et ne pas refléter les conditions locales qui influencent la consommation d’électricité ou tout simplement que les variables exogènes n’apportent pas de valeurs ajoutées.
| Modèle | Temps d’entrainement | Temps d’inférence |
|---|---|---|
| LGBM | 15 minutes | 2 secondes |
| TFT | 3 heures | 30 secondes |
Ces résultats ont été produits en utilisant des machines virtuelles sur AWS (Amazon Web Services). Ces machines virtuelles (VM) avaient les caractéristiques suivantes :
- G4dn.xlarge ;
- OS Ubuntu.
Travaux effectués, non intégrés à l’étude final
- Données IDF Mobilités : au départ, nous souhaitions utiliser un autre jeu de données, mais la complexité de celui-ci, nécessitant d’importants pré-traitements pour gérer les valeurs manquantes, nous a poussé à retirer ces données de notre étude ;
- Informer : des travaux ont été menés pour intégrer un autre modèle de Transformers, l’Informer, afin de le comparer aux TFT et LGBM. Son implémentation ne nous a pas permis d’avoir des résultats satisfaisant sur le jeu d’entrainement ce qui nous a poussé à le mettre de côté pour notre benchmark.
Nos recommandations
- Nous recommandons l’utilisation du modèle LGBM pour le forecasting à long et moyen terme en raison de ses meilleures performances, de son temps d’entraînement rapide et de sa facilité d’implémentation ;
- Bien que les modèles TFT puissent offrir de meilleurs résultats que le LGBM, les coûts élevés d’entraînement nous amènent à privilégier le LGBM. Dans les cas où une amélioration marginale de la performance est absolument nécessaire, quel qu’en soit le coût, il pourrait être utilisé.
Lors de ce projet, nous nous sommes concentrés sur des modèles comme le TFT et l’Informer. Pendant la réalisation de ces travaux, plusieurs nouveaux modèles prometteurs ont été publiés comme TimeGPT (Nixtla). Ces nouveaux modèles seront potentiellement l’objectif de nos prochains travaux, notamment en fonction des différents retours d’expérience de nos clients.
Références
La mission de l’expertise Time Series est d’exploiter le potentiel de vos séries temporelles à l’aide de solutions d’IA : analyse des données historiques, prévisions de demande, de parts de marché, de production, détection d’anomalies sur des données IoT.

Data Scientist
Data Scientist passionné par l’IA et ses applications dans les divers secteurs du monde du conseil. Je participe également aux projets R&D dans l’expertise Time Series, notamment dans le domaine du Deep Learning et de l’imputation des données.

Senior Data Scientist
Data Scientist passionnée par la prévision des séries temporelles, je collabore avec d'autres experts sur une variété de projets allant de l'imputation à la prévision en passant par l'analyse. Mon rôle actuel me permet de continuer à explorer et à repousser les limites dans le domaine de la prévision de séries temporelles et de la lecture automatique des documents.

Data Scientist
Passionné par le domaine des données, ainsi que par ses défis scientifiques, techniques et commerciaux. Mon poste actuel chez Capgemini Invent me permet de continuer à explorer les outils de data science et les approches analytiques, de repousser mes limites et d'améliorer mes connaissances.