

Intelligence artificielle de confiance : en route vers la responsabilité by-design

L’intelligence artificielle de Confiance est un sujet que l’on adresse tous les jours chez Quantmetry pour fournir à nos clients des algorithmes de qualité. Ce sujet est traité par l’expertise Reliable AI qui assure la connaissance et l’application de l’État de l’Art des 8 thématiques de l’IA de Confiance introduites dans cet article. La responsabilité est une de ces 8 composantes.

La responsabilité, à quoi ça sert ?
L’usage de l’intelligence artificielle explose et infuse déjà tout le tissu économique. Chaque cas d’usage porte des risques de différents niveaux de gravité et pose des questions fondamentales, trop rarement traitées : Quel impact en cas d’erreur ? Qui est le responsable en cas de problème ? Quels sont les risques ? Comment assurer leur possible remédiation ? Quelle gouvernance apporter pour sécuriser l’utilisation d’algorithme ? Comment assurer leur auditabilité ? La responsabilité permet justement aux entreprises de rendre des comptes sur les décisions prises de manière automatique ou semi-automatique, et de s’en porter garant devant la loi et les consommateurs.
La responsabilité, qu’est-ce que c’est ?
Si nous ouvrons notre dictionnaire Larousse, la responsabilité est : une « obligation ou nécessité moral de répondre, de rendre compte et de se porter garant de ses actions ou de celles des autres ». Traduit dans le contexte de l’intelligence artificielle, la responsabilité repose sur 6 concepts.
Transparence
« Dire ce que l’on fait et faire ce que l’on dit », un vieux dicton qui s’applique tout particulièrement quand on parle de gouvernance et de documentation. Un algorithme arrive rarement seul, règles métiers, modèles de machine learning… il est important de documenter clairement l’ensemble de la chaine algorithmique ainsi que les prises de décisions humaines. La documentation des différentes parties prenantes et leurs responsabilités doivent également permettre de rendre les systèmes d’IA opérables. Afin d’avoir une approche solide, il est également important de pouvoir justifier les choix qui ont été pris dans la vie du projet, les hypothèses émises et les différentes décisions prises qu’elles aient été fonctionnelles ou techniques. En dernier lieu dès le moment où un être humain interagit avec une IA, l’information doit lui être communiquée systématiquement de manière visible.
Traçabilité
Afin de pouvoir effectuer une maintenance efficace d’algorithmes en production il faut pouvoir être auditable et cela en démontrant la capacité à tracer l’ensemble de la chaîne de traitement dans le temps et à la remonter pour inspection puis identification de causes racines. La reproductibilité des différents éléments de la chaine algorithmique va très souvent être la condition sine qua pour résolution de problèmes en production. Cela permet également d’identifier les manquements en cas d’accidents.
Contrôle des risques
Souvent, en production, lorsque l’on commence à opérer un système, à le maintenir, à le faire évoluer, il n’est pas rare de découvrir certaines situations impactantes qui n’avaient pas été imaginées en amont. Ces risques, découverts bien trop tard en général, pouvant avoir de lourds impacts financiers, éthiques, réputationnels ou opérationnels, doivent être anticipés, priorisés et des méthodes de préventions adéquates doivent être mises en place.
Un exercice d’anticipation des risques, à faire le plus tôt dans le projet, dès le cadrage, doit permettre de s’assurer que les pires scénarios ont bien été identifiés, quantifiés en termes d’impact et de probabilité d’occurrence. Cette analyse de risques est également le bon moment pour identifier si l’algorithme est à considérer comme à risques vis-à-vis de la future réglementation européenne, l’AI Act.
Vie Privée
La donnée est un des aliments préférés des modèles d’intelligence artificielle. Si la bonne gestion de la qualité de données est souvent synonyme de performance, le respect de la vie privée, du droit à l’oubli et plus généralement du cadre réglementaire RGPD (Règlement Général pour la Protection des Données) est la condition sine qua none à l’utilisation des données personnelles. Le principe de minimisation est à prendre en compte : ne travailler qu’avec les données strictement nécessaires au besoin pour une finalité donnée et avec le consentement des personnes concernées.
Contrôle humain
Si un accident apparait sur une ligne de production, il viendra à l’idée de chacun d’entre nous d’appuyer sur le premier bouton rouge « STOP » à proximité. Ce bouton a sa place également dans l’opération d’algorithmes de machine learning et est même une obligation pour les cas d’usages considérés comme risqués vis-à-vis de l’AI Act.
La conception technique va toujours de pair avec l’identification du besoin métier initial et la manière dont va être utilisé l’algorithme une fois en production. Il faut se poser la question de son autonomie. Est-ce qu’il agira en totale autonomie (human-out-of-the-loop), est-ce qu’il propose, et agit uniquement si la validation humaine est donnée (human-in-the-loop) ou est-ce qu’il n’aura pour rôle que de faire des recommandations qu’un humain peut choisir de suivre ou d’ignorer (human-support). Sur un même cas d’usage, un algorithme en complète autonomie porte par essence plus de risques que celui qui donne une recommandation.
Cybersécurité
Les attaques malveillantes n’ont pas attendu l’avènement du machine learning pour occuper les experts en cybersécurité. Cependant de nouvelles techniques d’attaques adverses voient le jours dont certaines plus spécifiques aux algorithmes de machine learning : empoisonnement, évasion, extraction de modèle, vol de données. Les buts sont multiples, l’espionnage industriel (modèle volé et reproduit), baisse des performances des modèles en production ou impact direct sur le comportement du modèle (ex : acceptation automatique des crédits bancaires si une combinaison des données d’entrées spécifique est validée).
Avec l’émergence d’IAs de plus en plus sophistiquées, la surface d’attaque à surveiller par les équipes de cybersécurité s’étend et va demander un rapprochement encore plus fort des équipes IT et data.
La responsabilité, comment l’activer ?
Afin d’assurer la maitrise des responsabilités autour d’un algorithme, trois actions à minima sont à mettre en place dans les projets IA.
Anticiper
La première action à effectuer dès le cadrage du projet est de faire une analyse de risques et de recenser tous les scénarios redoutés du cas d’usage en production. Ces scénarios peuvent venir de projets similaires en production en interne, de la presse, d’autres sociétés ou de scénarios imaginés. Un atelier d’anticipation permet de consolider l’identification ainsi que la qualification (impact et probabilité) de tous les risques possibles (opérationnel, financiers, légaux, éthiques, …). Pour optimiser cet atelier, il est bon de prévoir un panel diversifié de parties prenantes.
Le résultat de cet atelier est à consolider dans un DUERP, Document d’Évaluation des Risques en Production.
Documenter
La deuxième action est de construire une documentation complète et autoporteuse de l’ensemble du projet. Documenter prend du temps et il peut être difficile de savoir si on a fait assez, trop et, surtout, si on a documenté les bonnes choses. Afin de rendre le modèle opérable et maintenable pour les équipes la documentation doit contenir à minima la documentation de la chaine de décision complète (qui prend la décision et quand ?), de la chaine algorithmique, du cycle de vie des modèles, de l’infrastructure du projet et de l’expérience utilisateur. Ces différents éléments sont à consolider en trois volets distincts : fonctionnel, scientifique et technique.
Historiser
L’opérabilité d’un système passe également par sa traçabilité. Sans traçabilité, les capacités d’identification de causes racines, de maintenance ou d’audit sont grandement limitées. Pour garantir ces éléments, il est important de tracer les décisions métier finales, de pouvoir remonter aux prédictions techniques, au modèle utilisé ainsi qu’à son jeu d’entrainement. Le logging de ces informations, de la version du modèle actuel en production et l’historisation de quel modèle était en production à quel moment est à mettre en place.
Une possibilité est de créer une base de données de décisions métiers et des prédictions associées ainsi qu’un registre de modèles pointant vers leurs données d’entrainement.
La responsabilité, en vrai ça donne quoi ?
Afin d’illustrer ces concepts, voici un process que nous avons pu construire et intégrer à la gestion de projet existante chez un de nos clients et cela afin d’améliorer la gouvernance des projets d’intelligence artificielle.
Nous avons travaillé sur deux méthodes en parallèle : rattraper la dette de responsabilité et construire des nouveaux cas d’usage responsables by-design.
Rattraper la dette
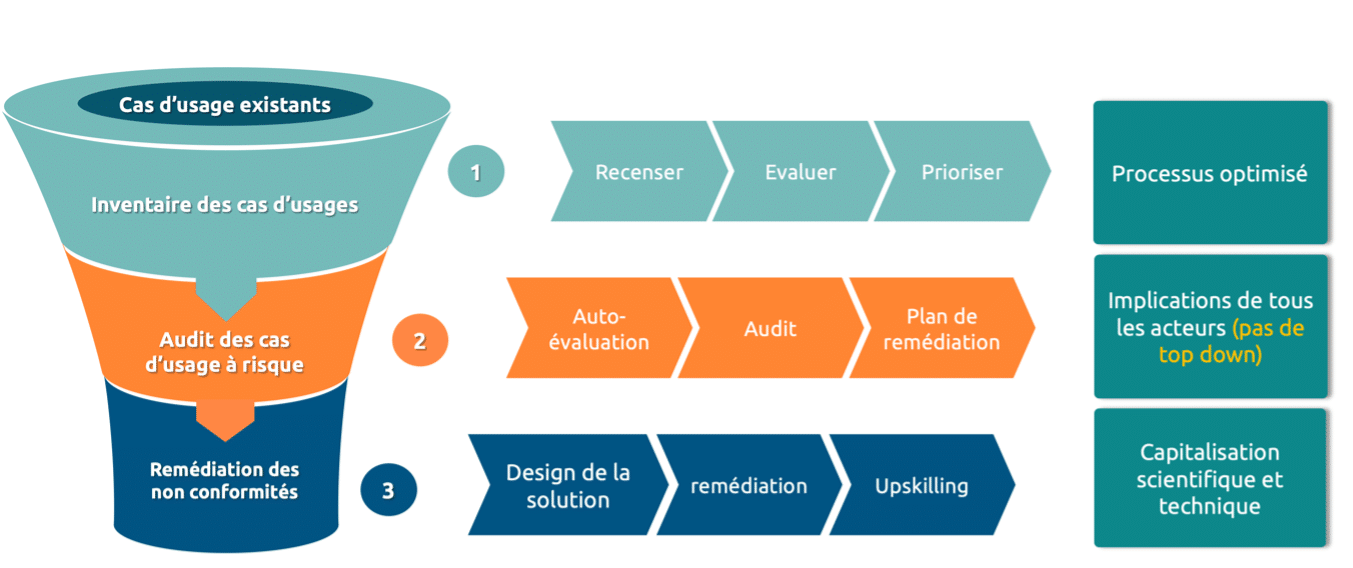
Figure 1 : méthodologie Quantmetry de rattrapage de la dette des cas d’usage. Tout commence par une phase d’inventaire des cas d’usage, suivi d’un audit ciblé des cas les plus à risque, avec planification des solutions de remédiation pour chacun.
La première étape a été de rattraper la dette de confiance, et de traiter les projets historiques toujours en cours de développement ou de maintenance. Nous avons réalisé la cartographie des différents projets existants et en cours de cadrage et nous les avons priorisés en fonction de différents principes : risques réglementaires, maturité, impact stratégique. Pour donner suite à cette priorisation, nous avons identifié le top-k que nous avons audité sur les huit axes de l’IA de confiance (voir cet article détaillé sur notre méthodologie d’audit interne). A la suite de l’audit, chaque cas d’usage est reparti avec un plan de remédiation chiffré, et intégré aux futurs développements. Dans cette approche, nous avons pris le rôle d’un tiers de confiance venant auditer un état existant.
Construire des cas d’usage responsables by-design
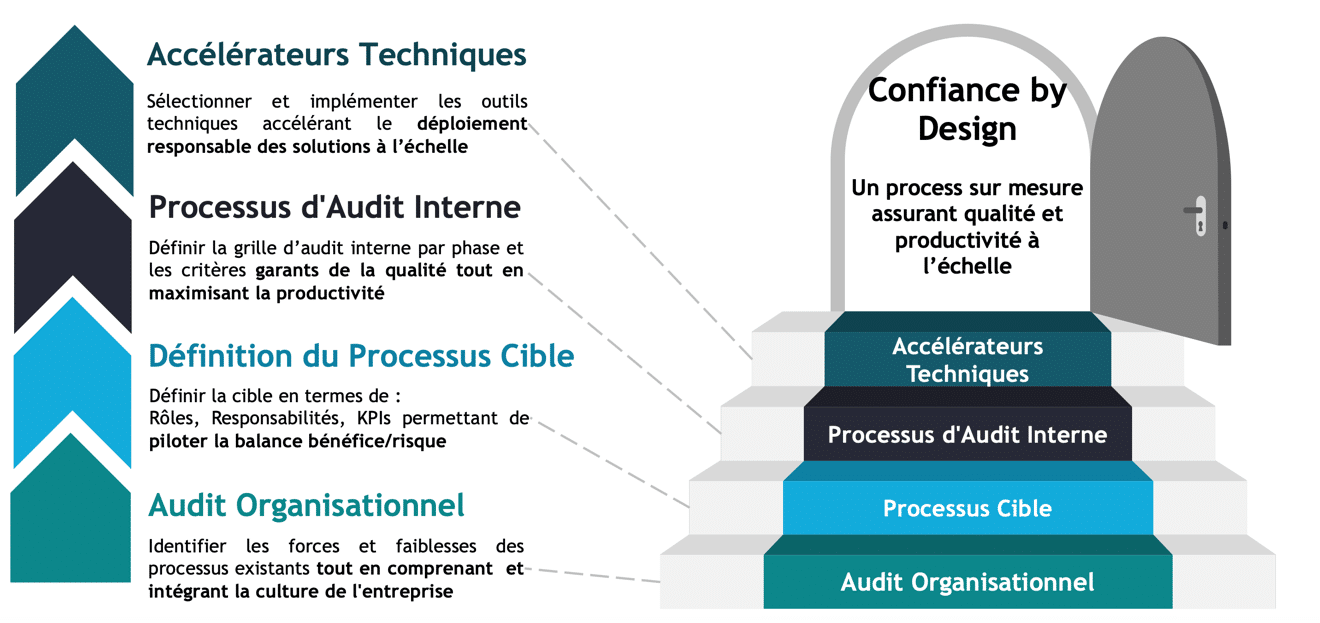
Figure 2: méthodologie Quantmetry de mise en place de la confiance by-design. On commence par un audit organisationnel permettant de cartographier les processus existants, on conçoit ensuite un incrément et un processus cible. Un des éléments phares de ce processus est la mise en place d’une logique d’audit interne, qui donne lieu à des plans de remédiations appuyés par des accélérateurs techniques.
En parallèle de la remédiation du patrimoine existant, nous avons adressé la conception de systèmes d’IA responsables by-design. Nous avons commencé par cartographier les processus existants afin de s’y insérer naturellement sans rajouter une surcouche au mille-feuille organisationnel. Nous avons ensuite travaillé avec les équipes client à la création d’une méthodologie de suivi de projet IA à utiliser tout au long du projet, de la conception à l’industrialisation des algorithmes, jusqu’aux étapes de maintenance. Chaque projet est donc à chaque étape et doit fournir des garanties de transparence et de responsabilité pour débloquer le budget des phases suivantes. Ce suivi de projet est renforcé par une logique d’audit interne, permettant de mesurer et remédier régulièrement les gaps de conformité attendus. Enfin, nous avons développé des outils permettant d’accélérer les étapes de conception et d’audit, comme des templates de code, de documentation ou des guides pratiques d’implémentation d’IA responsables, compatibles avec les attendus de l’audit interne.
Finalement, mettre en place des processus de conception et de suivi d’IA responsable a permis au client :
- D’augmenter la qualité de ses projets et d’accélérer les phases d’audit
- De sécuriser le transfert de connaissances dans un cycle de vie projet
- D’assurer la conformité réglementaire des projets
- D’engager les collaborateurs autour de thématiques qui font sens
Bref, l’IA responsable, ça vous gagne !
Les membres de l’expertise Reliable AI développent des modèles performants, fiables et maîtrisés, sur l’ensemble du cycle de vie, pour une IA de confiance.

Manager de l’expertise Reliable AI
Avec aujourd’hui plus de 10 années d’expérience en conseil et la mise en œuvre de projets data, j’aide nos clients à la mise en place d’une IA de confiance avec une expertise en interprétabilité des modèles et en gestion de leur cycle de vie en production.